Criando avatares com I.A.
Recentemente tivemos um BOOM gigante no uso de inteligências artificiais que geram imagens. Primeiro tivemos os modelos da OpenAI, os famosos DALL-E e DALL-E 2, depois surgiram o Midjourney e oStable Diffusion. Por sua vez as BigTechs também não poderiam ficar de fora, com a Meta anunciando o Make-A-Video, que é semelhante aos outros modelos, mas dessa vez ele cria um vídeo a partir de uma imagem e a Google com o Stable DreamFusion, modelo que cria objetos em 3D. Realmente 2022 foi o ano da IA gerando arte.
A partir desses modelos e suas APIs, vários desenvolvedores começaram a fazer vários apps para smartphone que automatizam o uso dessas IAs. Nessa última semana de novembro de 2022, um app que ficou muito famoso foi o Lensa criado pela Prisma Labs, mesma empresa que tem o app Prisma, que em suma tinha uma ideia semelhante ao Lensa só que era mais voltado para a edição e não geração de imagens. Infelizmente o Lensa é pago, mas se você também estava curioso para testar essa IA, fique calmo, a IA em si é open-source, gratuita e não precisa de tanto conhecimento para utilizá-la.
Mas, antes de botar a mão na massa, vamos primeiro conhecer alguns modelos e como você pode usá-los.
Criando Imagens Diversas
Se você não tem computador, ou ele não é muito potente, uma saída é utilizar os modelos em nuvem da OpenAI ou o Midjourney.
Os modelos DALL-E da OpenAI estão agora abertos para o público, sendo assim, você pode entrar nesse site se registar e começar a usar, um único detalhe é que esse modelo possui algumas restrições em relação a rostos, marcas, etc. Sendo assim alguns prompts que você utilizar podem sair meio distorcidos de alguma forma. Além disso você não tem prompts ilimitados, a OpenAI te dá um espécie de crédito todo mês(referente a quantidade de prompts disponíveis) e caso queira utilizar mais e não quiser esperar o próximo mês para recarregar você terá de pagar uma certa taxa. Para mais detalhes leia a documentação.
Já no caso do Midjourney, ele é baseado em um bot de Discord, sendo assim, crie uma conta no Discord, entre no site deles siga as instruções que eles te passam e se divirta :)
Agora, se maquina disponível não é um problema para você, o recomendável é utilizar o StableDiffusion, para mais detalhes de uma olhada no site deles e também no github da Stability-AI.
Avatares
Agora que você conhece alguns do modelos que estão sendo usados hoje, vamos começar a criar alguns Avatares.
Como citado antes, o Lensa utiliza um modelo open-source, no caso o Stable Diffusion, utilizando um técnica, chamada de DreamBooth, que de maneira resumida, pega algumas imagens de entrada e a classe dessas imagens, e a partir disso ele gera um modelo personalizado de text-to-image, com isso você pode utilizar esse modelo para gerar imagens personalizadas a partir das entradas que você passou para ele antes.
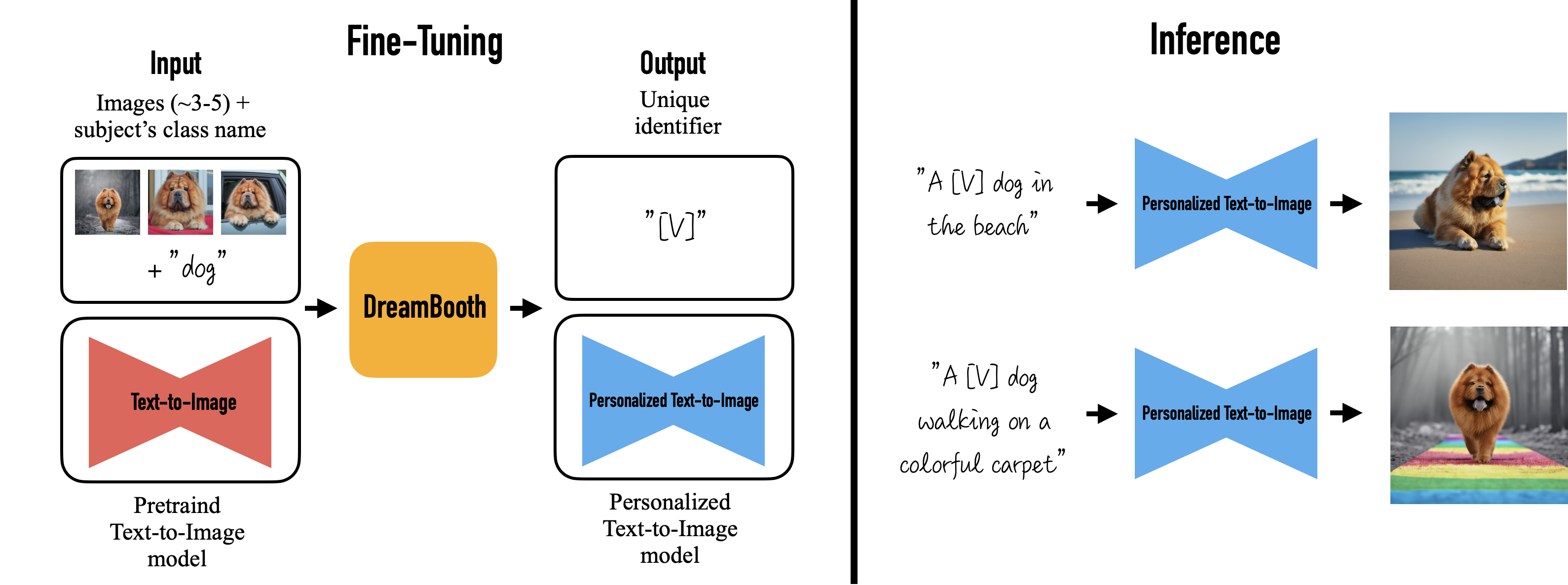
Com isso então, podemos utilizar um modelo já treinado para fazer nossas imagens, aqui utilizaremos um fork do modelo dísponivel no Github do huggingface criado pelo ShivamShrirao, do qual você pode encontrar aqui.
Fazendo o Avatar
1) Antes de tudo, tire por volta de 20 fotos suas, tente enriquecer os detalhes do seu rosto melhorando a iluminação, tirando fotos em vários ângulos, várias poses, várias expressões (alegre, triste, feliz, tédio) etc.
2) Com as fotos tiradas você deve padronizá-las em um tamanho de 512x512 px, para deixá-las dessa forma você pode usar photoshop, gimp, imagemagick, ou quaisquer outros editores e ferramentas disponíveis, eu acabei usando um site chamado birme, por agilizar a centralização do rosto.
3) Crie uma conta (é gratuito) no HuggingFace
Confirme seu e-mail!

4) Crie um token no HuggingFace, colocando um nome qualquer, evitando espaços e simbolos especiais, para ele e dando a permissão de escrita(write) (lembre-se de copiar o token e o nome dele, depois vamos usar essas informações no modelo)
5) Entre aqui e clique em aceitar, nessa parte você permite que o modelo interaja com sua conta do HuggingFace
obs: Caso não encontre nenhum botão para aceitar os termos, siga com o tutorial, caso ocorra algum erro no futuro, abra uma ISSUE
6) Abra o modelo no Google Colab clicando no botão ao lado
![]()
7) Sempre verifique se está usando uma GPU(Placa de vídeo poderosa do google), normalmente a Nvidia TESLA T4 com 15gb RAM (10gb para o treinamento do modelo).
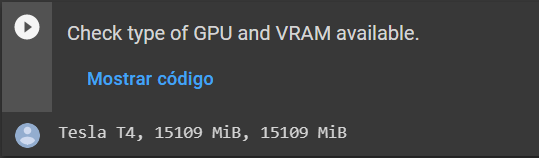
O google collab fornece um uso básico de GPU por algumas sessões limitadas diariamente depois ele bloqueia e aceita somente o uso de CPU. Não é possível usar CPU para treinar modelos ou gerar imagens.
8) coloque seu token criado no HuggingFace aqui:

9) Rode a seção Install Requirements
 Rodado com sucesso!
Rodado com sucesso!
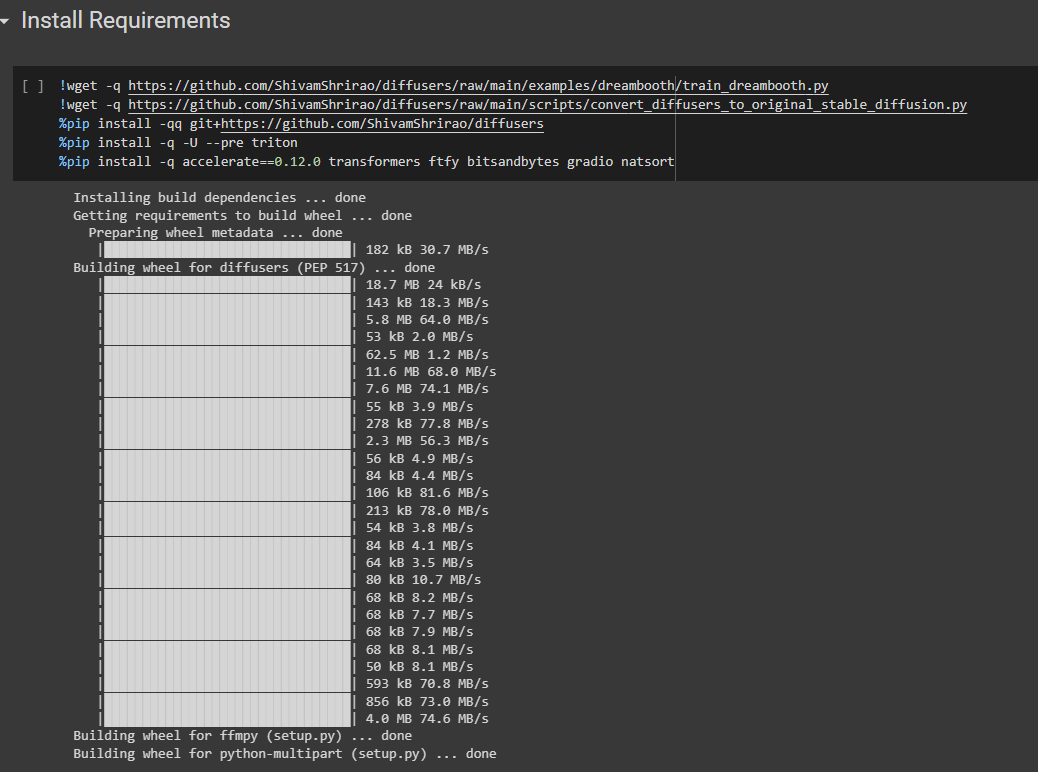
10) Rode Install xformers from precompiled wheel.
 Rodado com sucesso!
Rodado com sucesso!
 caso ocorra algum problema, troque por:
caso ocorra algum problema, troque por:
%pip install git+https://github.com/facebookresearch/xformers
obs: esse último comando pode demorar de 40min à 1h para terminar.
11) chegando nessa parte:
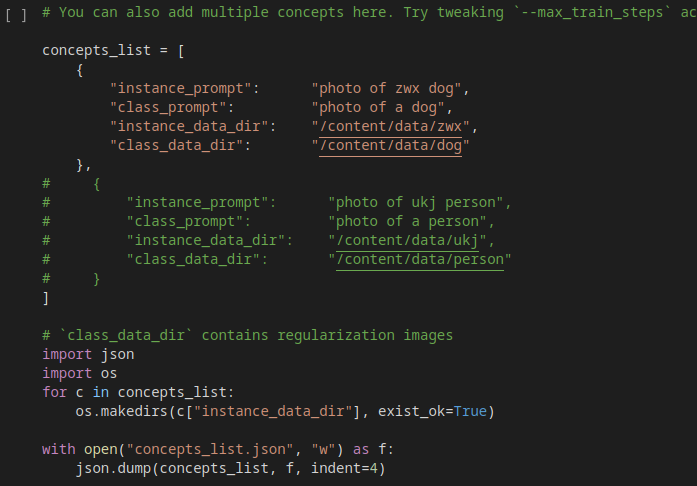
mude o código para esse abaixo (lembre de trocar o NOME_DA_SUA_TOKEN_AQUI para o nome que você colocou na sua token do HuggingFace)
concepts_list = [
{
"instance_prompt": "NOME_DA_SUA_TOKEN_AQUI",
"class_prompt": "photo of a person",
"instance_data_dir": "/content/data/NOME_DA_SUA_TOKEN_AQUI",
"class_data_dir": "/content/data/person"
}
]
import json
import os
for c in concepts_list:
os.makedirs(c["instance_data_dir"], exist_ok=True)
with open("concepts_list.json", "w") as f:
json.dump(concepts_list, f, indent=4)
Você verá que do lado direito você tem algumas pastas, entre em data > NOME_DA_SUA_TOKEN e aí dentro você arrasta todas aquelas fotos com 512 x 512 px
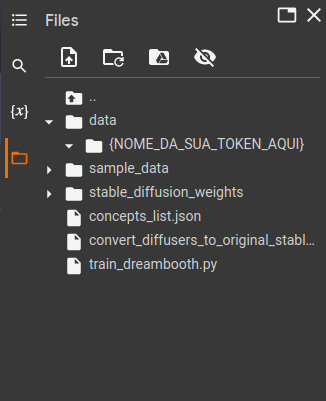
12) Após adicionar as imagens na pasta coloque o nome da sua token neste local:
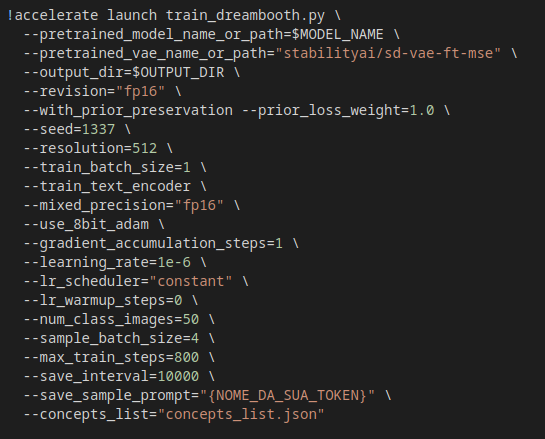
13) Insira aqui o valor: stable_diffusion_weights/zwx

14) Na seção Inference, mude a variável model_path de WEIGHTS_DIR para "stable_diffusion_weights/zwx/800"

15) Rode célula a célula até chegar na seção Run for generating images.
16) Insira o prompt
vá nessa parte do arquivo
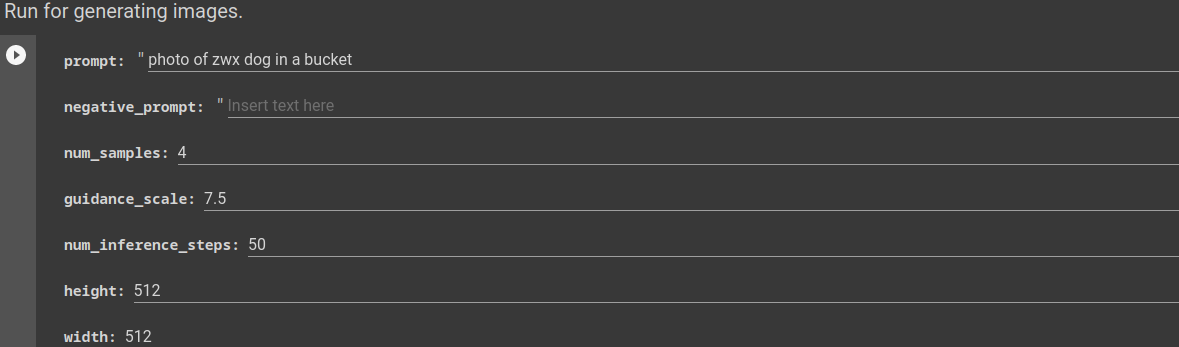
Adicione em prompt o texto que você quer que vire uma imagem. Caso você esteja empolgado, comece a brincar com esses parâmetros.
Se não souber por onde começar use algum site, como o Lexica, para utilizar alguns prompts que a comunidade já usou.
OBS: lembre-se sempre de adicionar o nome da sua token no texto que você vai colocar como entrada(prompt), dessa forma ele vai, de fato, gerar uma imagem com você
Problemas
Problema de Falta de GPU
Caso você não consiga acessar uma GPU significa que você deverá esperar no mínimo 12 horas para voltar usar a GPU. Você pode comprar um plano de uso do Google collab com mais tempo de GPU aqui: PRO Collab
______________________
Caso você encontre alguma dificuldade na execução do tutorial, sinta-se à vontade para abrir uma nova ISSUE.
Já se você encontrou algum problema e sabe como solucionar, também sinta-se à vontade para criar um PULL REQUEST.
OBS: Tome cuidado para não criar duplicatas
Créditos
Fiz esse tutorial após ver alguns stories da Gi Bordignon(aka spacecoding), por favor, dê uma olhada nos perfis dela, vale a pena ;)